Singapore's Sea-Lion v4 AI model fits on your laptop
Quantised multimodal LLM runs on a laptop with 32GB RAM.


The made-in-Singapore Sea-Lion v4 was released earlier this week, and it's the first multimodal model that will run on a laptop. Here's what we know about it.
What's Sea-Lion?
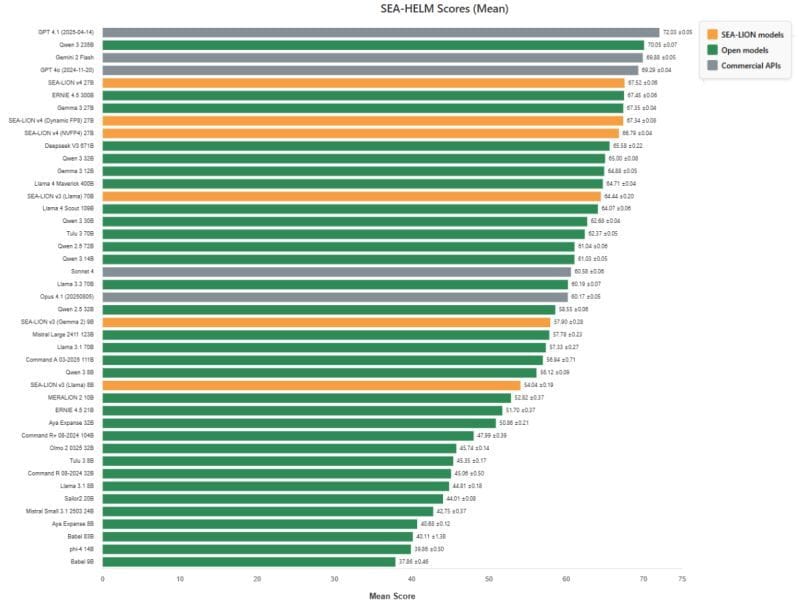
AI Singapore's Sea-Lion project was designed to understand and represent Southeast Asia's linguistic and cultural diversity. According to AI Singapore's Leslie Teo, Sea-Lion v4 is ranked number one among open models under the 200B parameters mark on the SEA-HELM benchmark.
I've previously spoken with Leslie about Sea-Lion, who shared his thoughts about ethical data sourcing, the strategy behind Sea-Lion, and why it was trained relatively cheaply.
Sea-Lion v4
I haven't had the chance to chat with Leslie again, but here's what we know about Sea-Lion v4. It's the first multimodal release in the Sea-Lion family, based on Google's Gemma 3 (27B), supports 128K token context windows, and was trained on 1 trillion tokens from Southeast Asian corpus.
And yes, the quantised versions of Sea-Lion v4 will run on a laptop with 32GB RAM. That's not a typo. A model that understands Southeast Asian languages and can process images fits on hardware you probably already own.
Because Sea-Lion v4 is licensed under the commercially permissive Gemma license, you can use it in commercial deployments. No need to worry about licensing restrictions or enterprise agreements.
The infrastructure reality check
As I wrote previously, the original Sea-Lion v1 was created with a lean team of just 20 Singaporeans. It was trained using 8x Nvidia A100 GPUs, and if I recall correctly, took less than a month of GPU time to train from scratch.
The team has since switched tactics. Sea-Lion v2 was created with Meta's Llama 3 using pre-training and fine-tuning. This brought training time down to just two days with 64x Nvidia H100 GPUs. That's a massive reduction in computational requirements.
Yesterday, I wrote about the rack-level power requirements of enterprise data centres, suggesting that 40-50kW should be adequate for a future-proofed deployment. From the figures above, it's clear that even a major LLM initiative like Sea-Lion, with a budget in the tens of millions (SGD), doesn't need many GPUs when using pre-training techniques.
So why would the average enterprise with just a handful or a score of GPUs require AI data centre-level rack density? They wouldn't.



